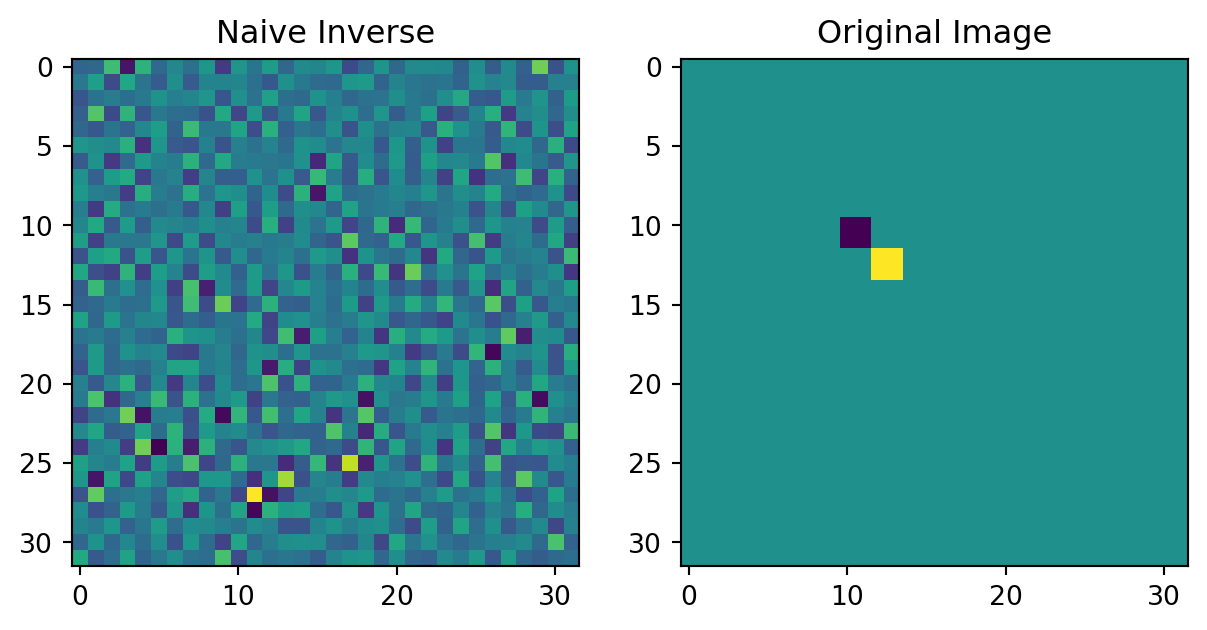
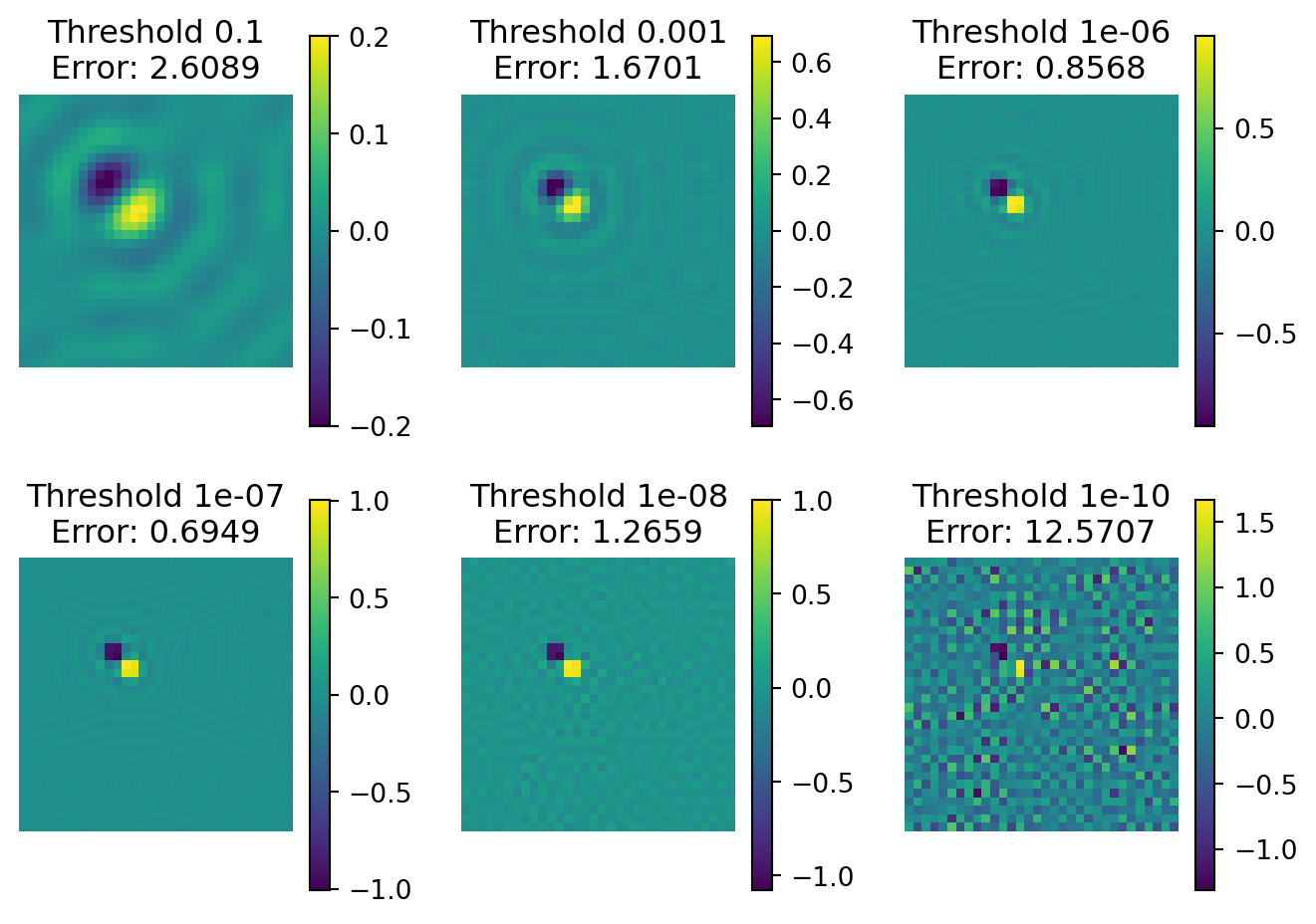
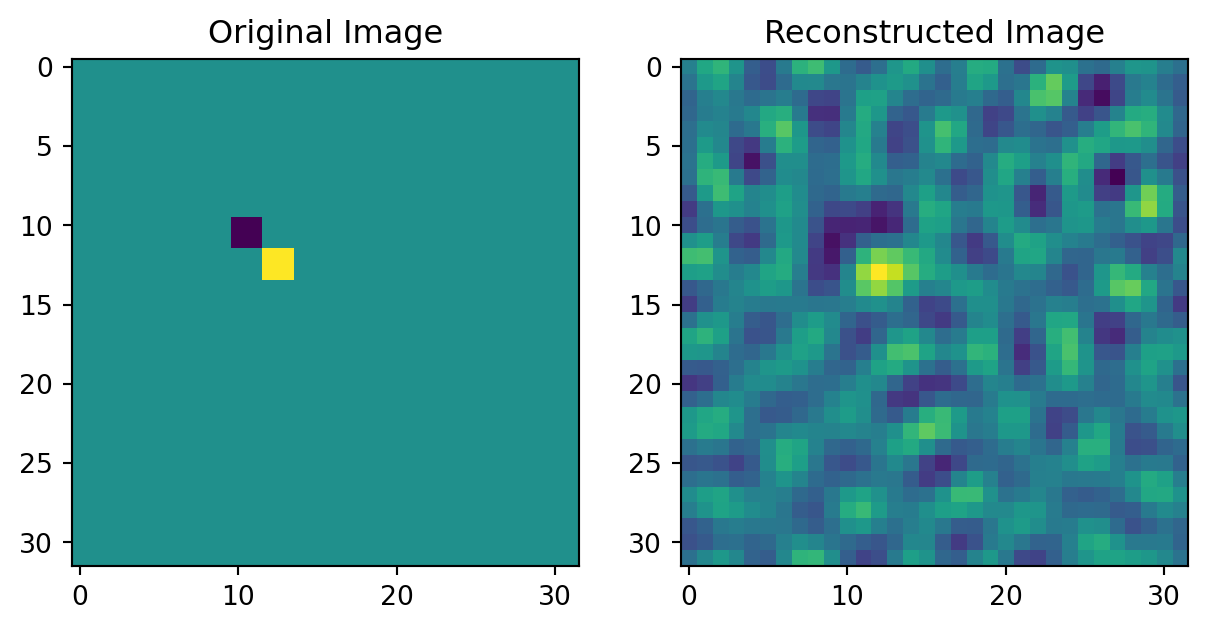
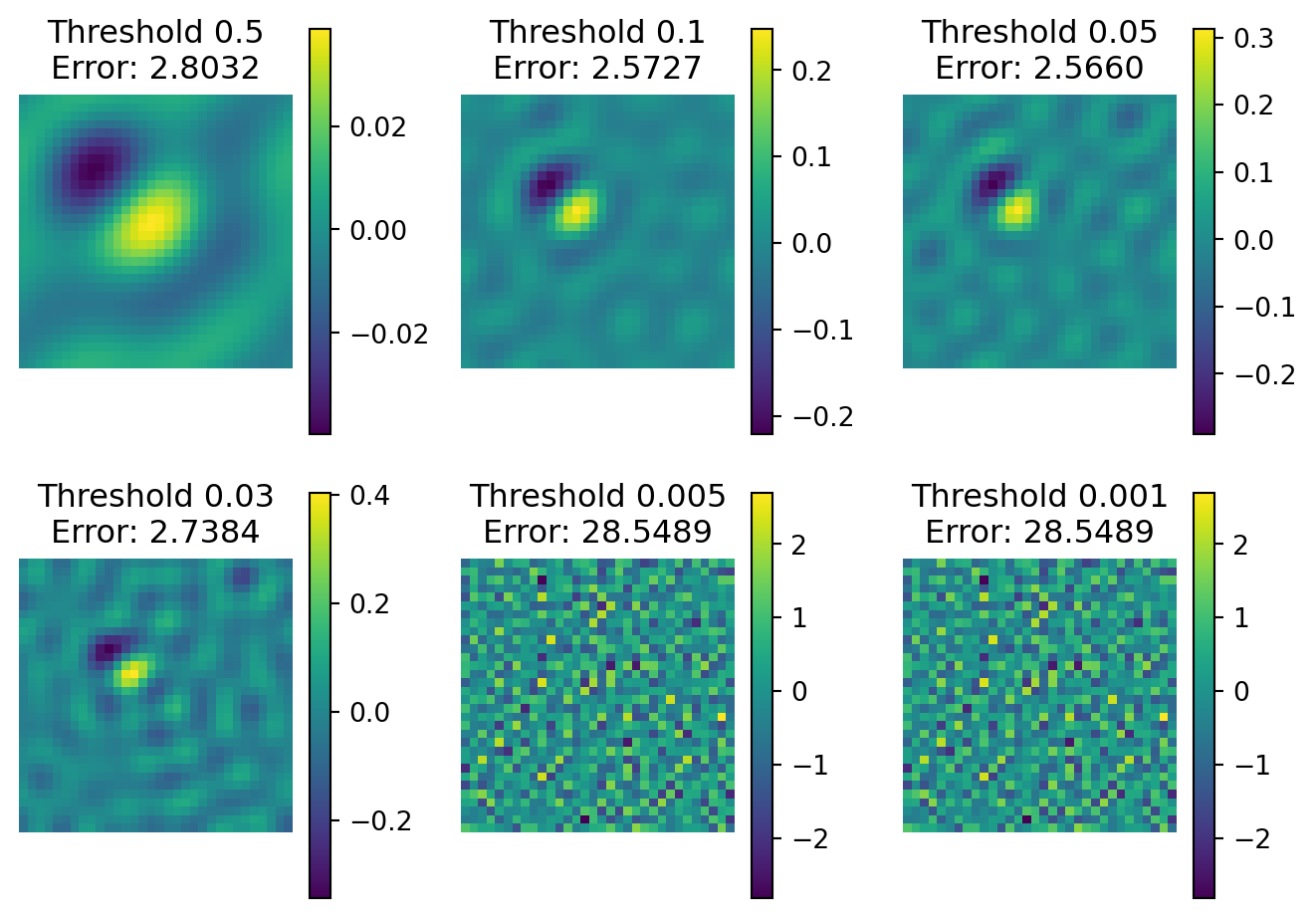
class gaussianConv(nn.Module):
"""
A PyTorch module that applies a Gaussian convolution to an input image using
a parameterized Gaussian Point Spread Function (PSF). The PSF is derived
from a covariance matrix and the derivatives of the Gaussian are computed
for edge detection.
Args:
C (torch.Tensor): Inverse of covariance matrix used to define the shape of the Gaussian.
t (float, optional): Scaling factor for the Gaussian, default is np.exp(5).
n0 (float, optional): Scaling factor for the original PSF, default is 1.
nx (float, optional): Scaling factor for the derivative along the x-axis, default is 1.
ny (float, optional): Scaling factor for the derivative along the y-axis, default is 1.
"""
def __init__(self, C, t=np.exp(5), n0=1, nx=1, ny=1):
super(gaussianConv, self).__init__()
self.C = C
self.t = t
self.n0 = n0
self.nx = nx
self.ny = ny
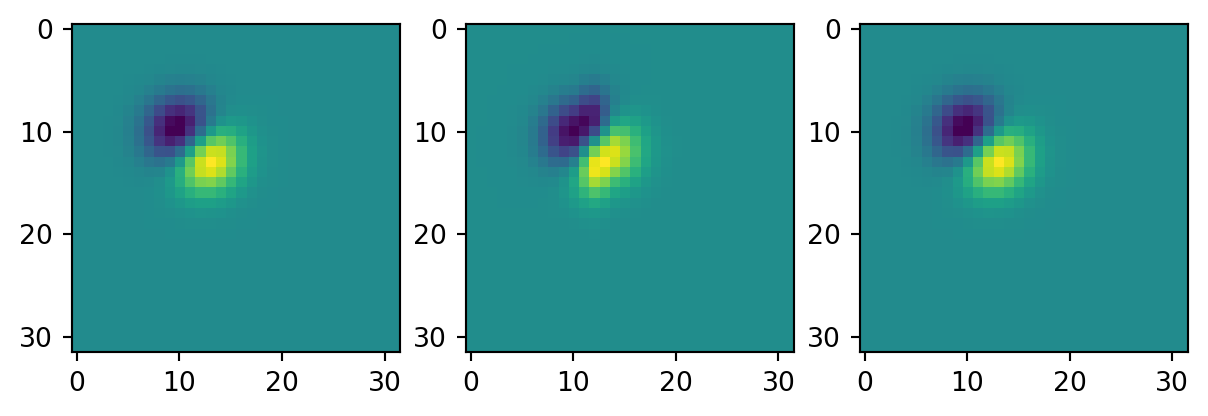
def forward(self, image):
"""
Apply the Gaussian convolution and derivatives to an input image.
This method performs convolution of the input image with a Gaussian
Point Spread Function (PSF) that includes the original Gaussian and
its derivatives along x and y axes. The convolution is performed
using the Fourier Transform for efficiency.
Args:
image (torch.Tensor): Input image tensor of shape (Batch, Channels, Height, Width).
Returns:
torch.Tensor: The convolved image of the same shape as the input.
"""
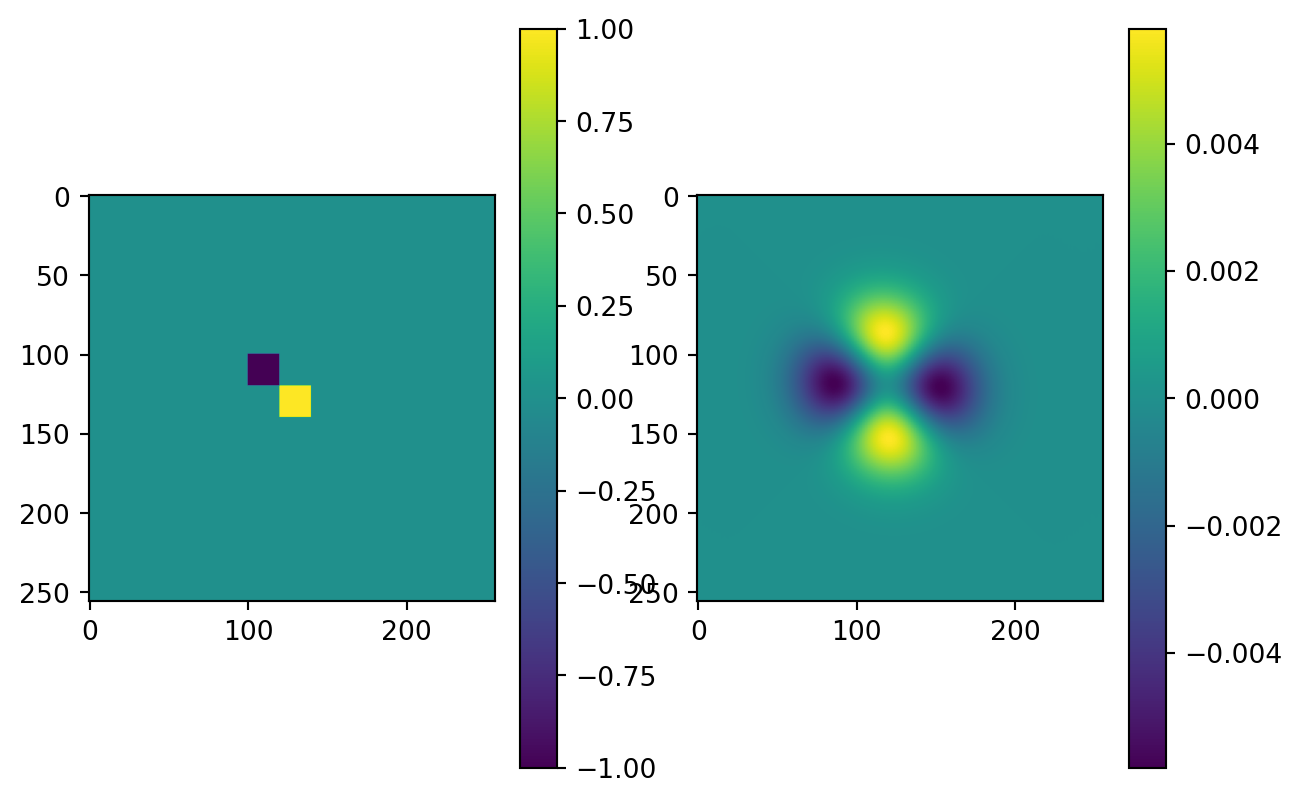
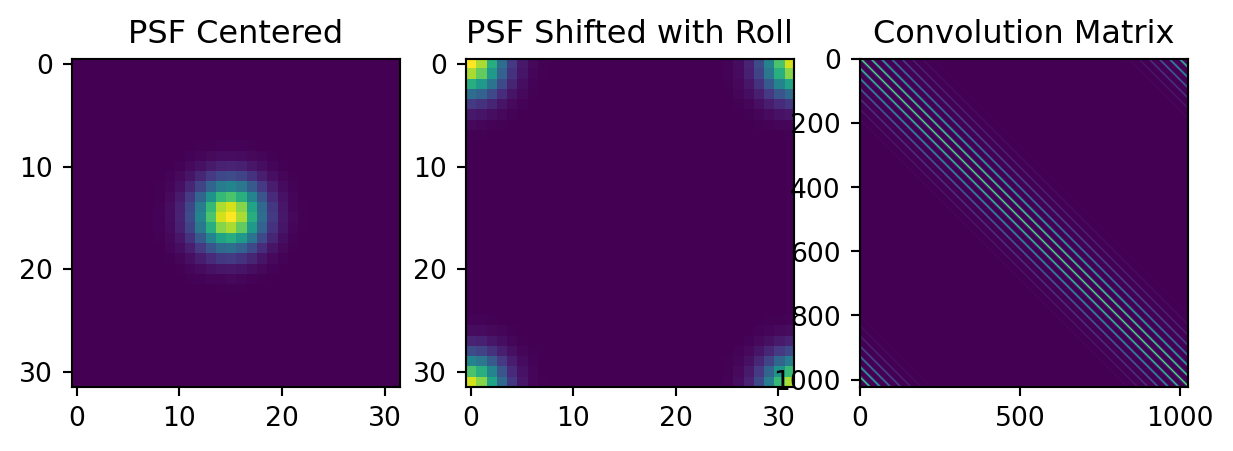
# Generate the PSF and calculate the center shift required for alignment
P, center = self.psfGauss(image.shape[-1], image.device)
# Shift the PSF so that its center aligns with the origin (top-left corner)
P_shifted = torch.roll(P, shifts=center, dims=[2, 3])
# Compute the Fourier Transform of the shifted PSF
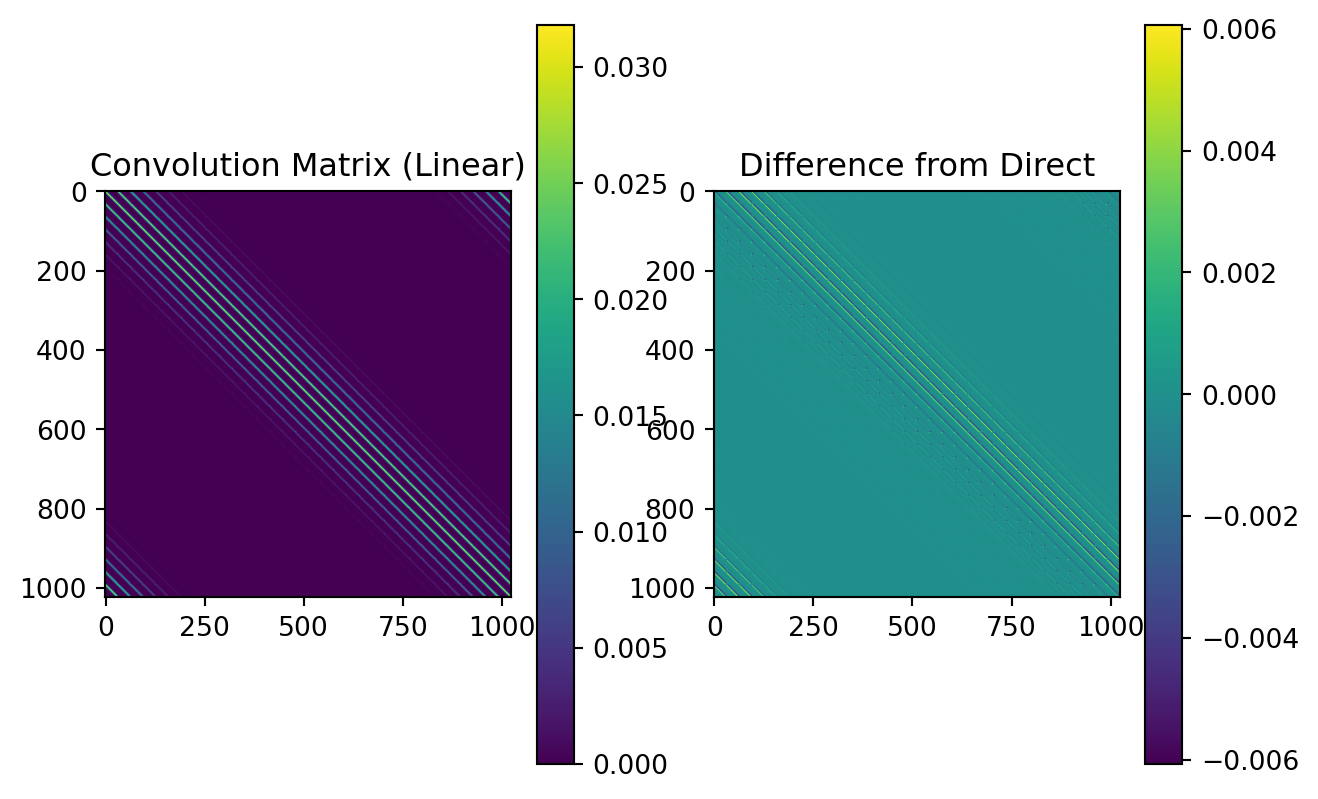
S = torch.fft.fft2(P_shifted)
# Compute the Fourier Transform of the input image
I_fft = torch.fft.fft2(image)
# Multiply the Fourier Transforms element-wise (convolution theorem with Hadamard product)
B_fft = S * I_fft
# Compute the inverse Fourier Transform to get back to the spatial domain
B = torch.real(torch.fft.ifft2(B_fft))
# Return the convolved image
return B
def psfGauss(self, dim, device='cpu'):
"""
Generate the Gaussian PSF and its derivatives.
Args:
dim (int): Dimension size (assumes square dimensions).
device (str, optional): Device to create tensors on, default is 'cpu'.
Returns:
tuple:
- PSF (torch.Tensor): The combined PSF including derivatives.
- center (list): Shifts required to align the PSF with the origin.
"""
# Define the size of the PSF kernel (assumed to be square)
m = dim
n = dim
# Create a meshgrid of (X, Y) coordinates
x = torch.arange(-m // 2 + 1, m // 2 + 1, device=device)
y = torch.arange(-n // 2 + 1, n // 2 + 1, device=device)
X, Y = torch.meshgrid(x, y, indexing='ij')
X = X.unsqueeze(0).unsqueeze(0) # Shape: (1, 1, m, n)
Y = Y.unsqueeze(0).unsqueeze(0) # Shape: (1, 1, m, n)
# Extract elements from the covariance matrix
# Assuming self.C is a 2x2 tensor
cx, cy, cxy = self.C[0, 0], self.C[1, 1], self.C[0, 1]
# Compute the Gaussian PSF using the meshgrid and covariance elements
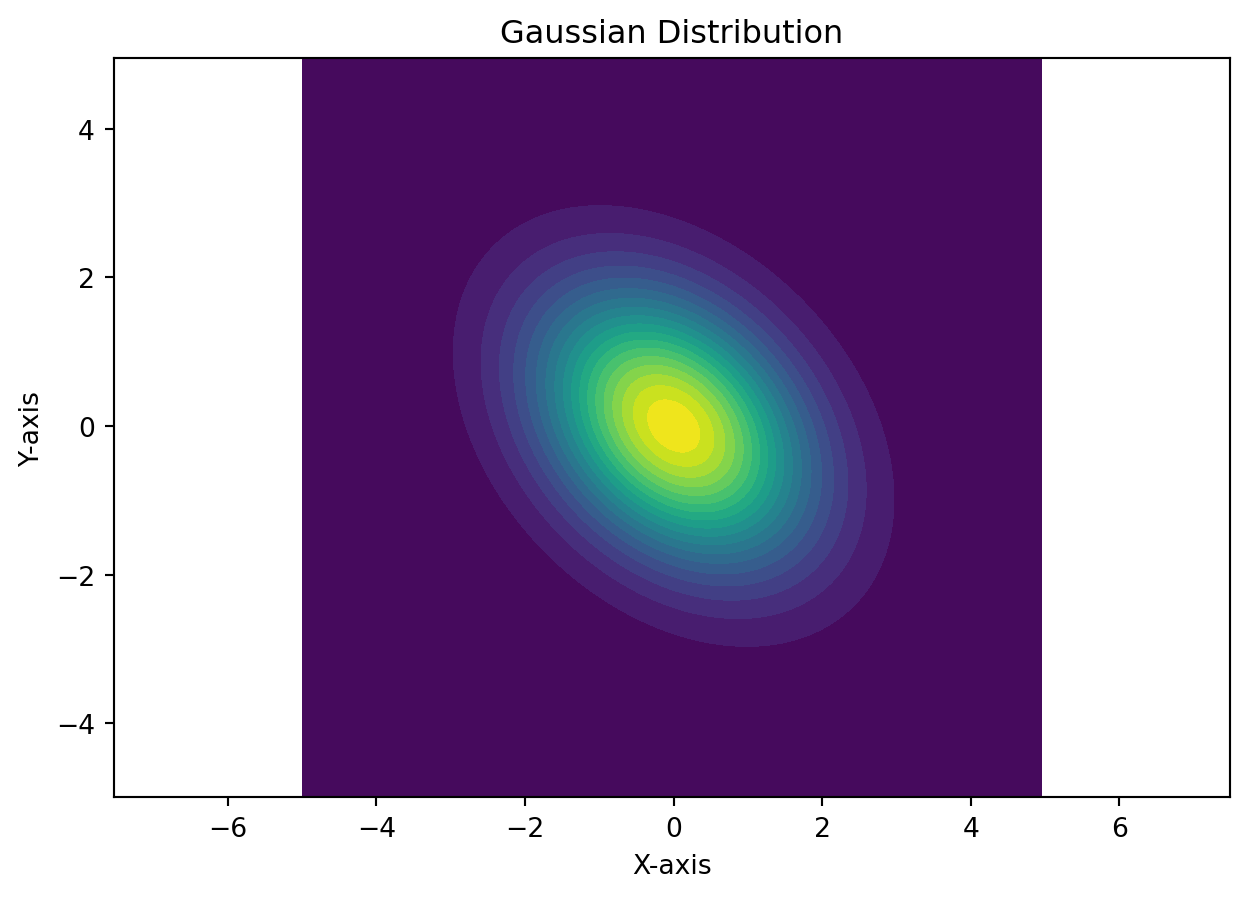
PSF = torch.exp(-self.t * (cx * X ** 2 + cy * Y ** 2 + 2 * cxy * X * Y))
# Normalize the PSF so that its absolute sum is 1
PSF0 = PSF / torch.sum(PSF.abs())
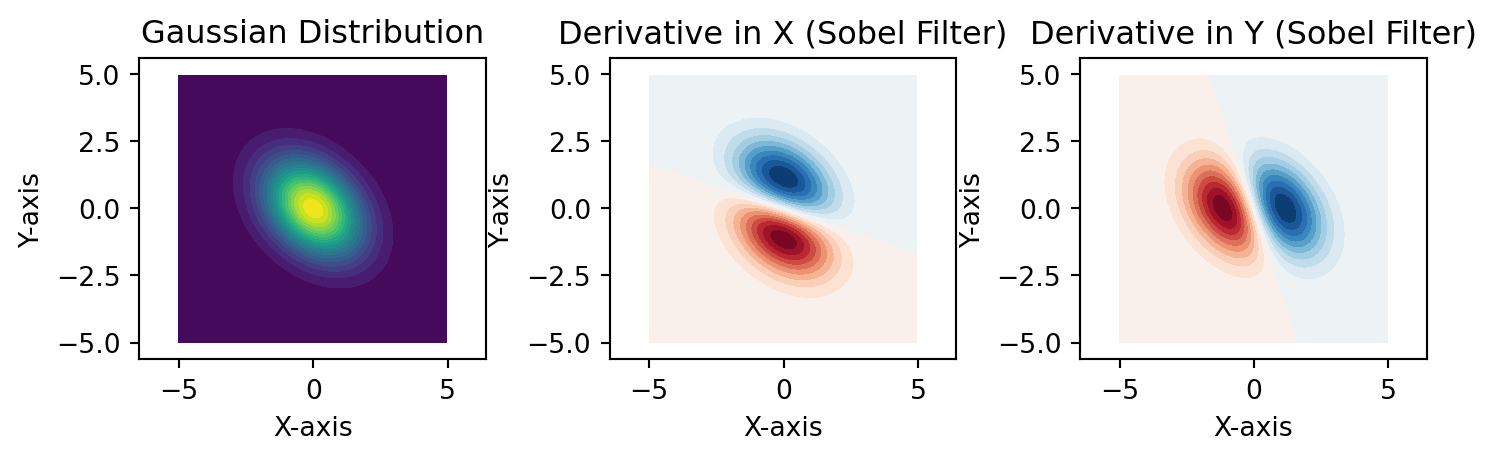
# Define derivative kernels (Sobel operators) for edge detection
Kdx = torch.tensor([[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]], dtype=PSF0.dtype, device=device) / 4
Kdy = torch.tensor([[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]], dtype=PSF0.dtype, device=device) / 4
# Reshape kernels to match convolution requirements
Kdx = Kdx.unsqueeze(0).unsqueeze(0) # Shape: (1, 1, 3, 3)
Kdy = Kdy.unsqueeze(0).unsqueeze(0) # Shape: (1, 1, 3, 3)
# Convolve the PSF with the derivative kernels to obtain derivatives
# Padding ensures the output size matches the input size
PSFdx = F.conv2d(PSF0, Kdx, padding=1)
PSFdy = F.conv2d(PSF0, Kdy, padding=1)
# Combine the original PSF and its derivatives using the scaling factors
PSF_combined = self.n0 * PSF0 + self.nx * PSFdx + self.ny * PSFdy
# Calculate the center shift required to align the PSF with the origin
center = [1 - m // 2, 1 - n // 2]
# Return the combined PSF and center shift
return PSF_combined, center