import matplotlib.pyplot as plt
import matplotlib
#matplotlib.use('TkAgg')
import numpy as np
import torch.optim
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
import copy
import seaborn as sns
import math
import os
import time
import matplotlib.pyplot as plt
import numpy as np
import torch.fft
class gaussianConv(nn.Module):
"""
A PyTorch module that applies a Gaussian convolution to an input image using
a parameterized Gaussian Point Spread Function (PSF). The PSF is derived
from a covariance matrix and the derivatives of the Gaussian are computed
for edge detection.
Args:
C (torch.Tensor): Inverse of covariance matrix used to define the shape of the Gaussian.
t (float, optional): Scaling factor for the Gaussian, default is np.exp(5).
n0 (float, optional): Scaling factor for the original PSF, default is 1.
nx (float, optional): Scaling factor for the derivative along the x-axis, default is 1.
ny (float, optional): Scaling factor for the derivative along the y-axis, default is 1.
"""
def __init__(self, C, t=np.exp(5), n0=1, nx=1, ny=1):
super(gaussianConv, self).__init__()
self.C = C
self.t = t
self.n0 = n0
self.nx = nx
self.ny = ny
def forward(self, image):
P, center = self.psfGauss(image.shape[-1], image.device)
P_shifted = torch.roll(P, shifts=center, dims=[2, 3])
S = torch.fft.fft2(P_shifted)
I_fft = torch.fft.fft2(image)
B_fft = S * I_fft
B = torch.real(torch.fft.ifft2(B_fft))
return B
def psfGauss(self, dim, device='cpu'):
m = dim
n = dim
# Create a meshgrid of (X, Y) coordinates
x = torch.arange(-m // 2 + 1, m // 2 + 1, device=device)
y = torch.arange(-n // 2 + 1, n // 2 + 1, device=device)
X, Y = torch.meshgrid(x, y, indexing='ij')
X = X.unsqueeze(0).unsqueeze(0) # Shape: (1, 1, m, n)
Y = Y.unsqueeze(0).unsqueeze(0) # Shape: (1, 1, m, n)
cx, cy, cxy = self.C[0, 0], self.C[1, 1], self.C[0, 1]
PSF = torch.exp(-self.t * (cx * X ** 2 + cy * Y ** 2 + 2 * cxy * X * Y))
PSF0 = PSF / torch.sum(PSF.abs())
Kdx = torch.tensor([[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]], dtype=PSF0.dtype, device=device) / 4
Kdy = torch.tensor([[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]], dtype=PSF0.dtype, device=device) / 4
Kdx = Kdx.unsqueeze(0).unsqueeze(0) # Shape: (1, 1, 3, 3)
Kdy = Kdy.unsqueeze(0).unsqueeze(0) # Shape: (1, 1, 3, 3)
PSFdx = F.conv2d(PSF0, Kdx, padding=1)
PSFdy = F.conv2d(PSF0, Kdy, padding=1)
PSF_combined = self.n0 * PSF0 + self.nx * PSFdx + self.ny * PSFdy
center = [1 - m // 2, 1 - n // 2]
return PSF_combined, center
dim = 32
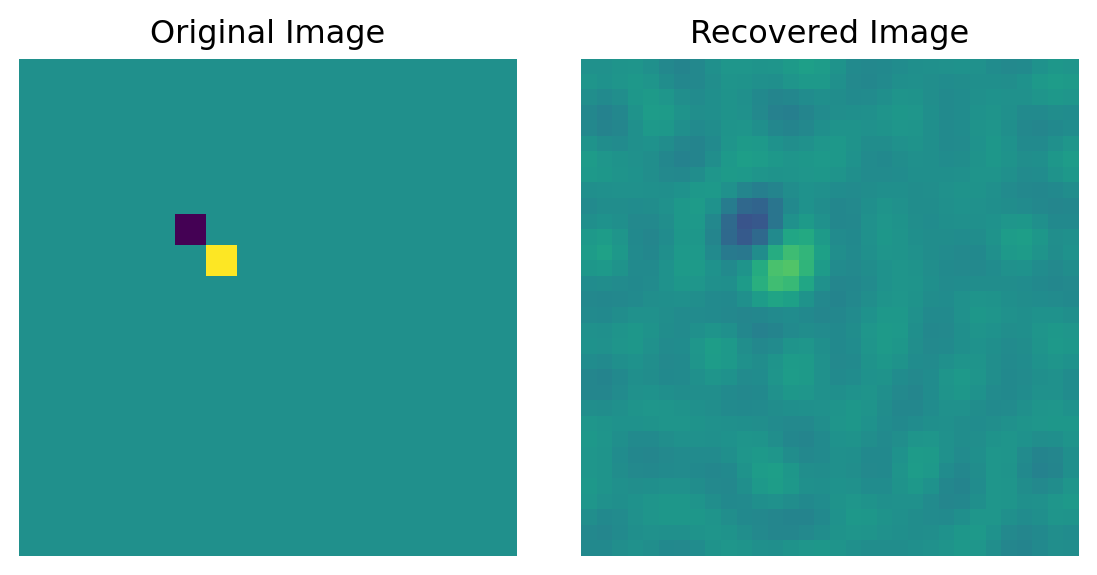
x = torch.zeros(1, 1, dim, dim)
x[:,:, 12:14, 12:14] = 1.0
x[:,:, 10:12, 10:12] = -1.0
C = torch.tensor([[1, 0],[0, 1]])
Amv = gaussianConv(C, t=0.1,n0=1, nx=0.1, ny=0.1)
n=(len(x.flatten()))
Amat = torch.zeros(n,n)
k=0
for i in range(x.shape[-2]):
for j in range(x.shape[-1]):
e_ij = torch.zeros_like(x)
e_ij[:,:, i, j] = 1.0
y = Amv(e_ij)
Amat[:, k] = y.flatten()
k = k+1
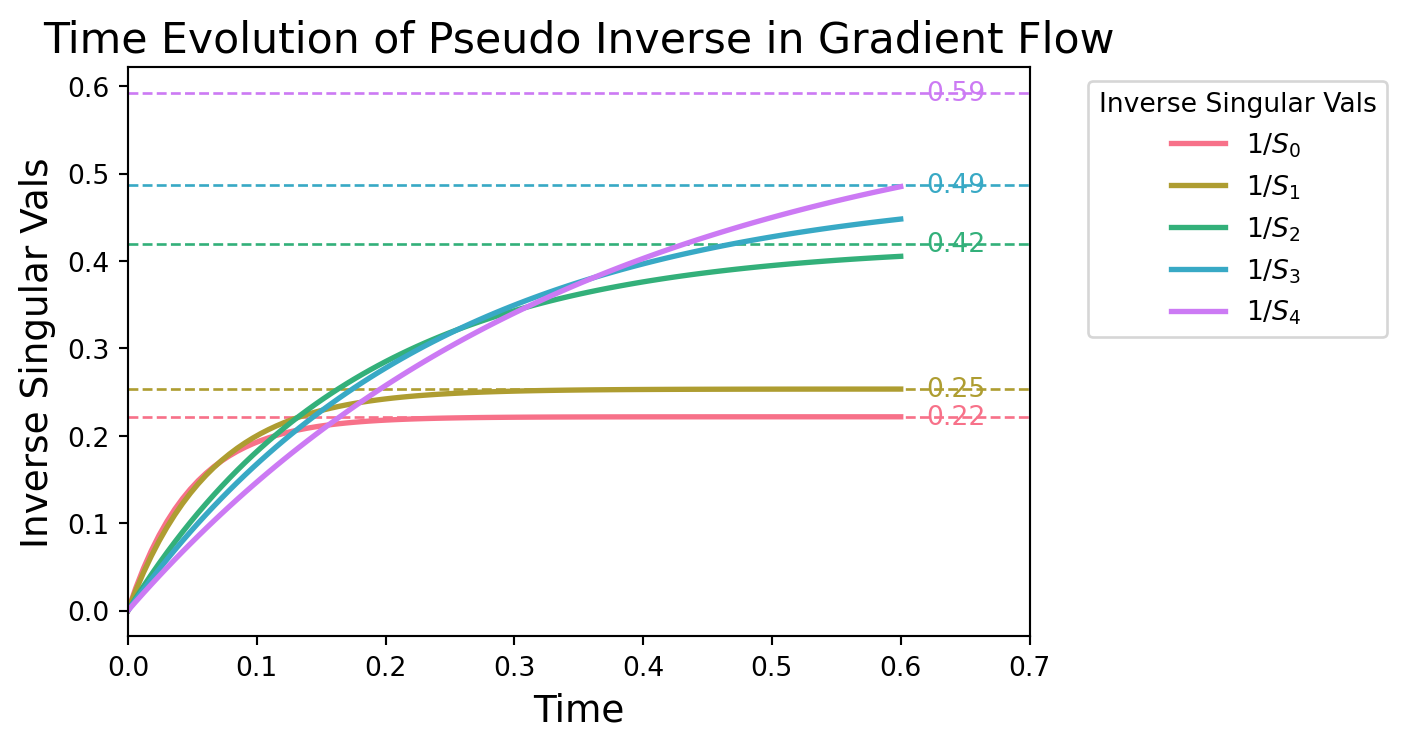
U, S, V = torch.svd(Amat.to(torch.float64))
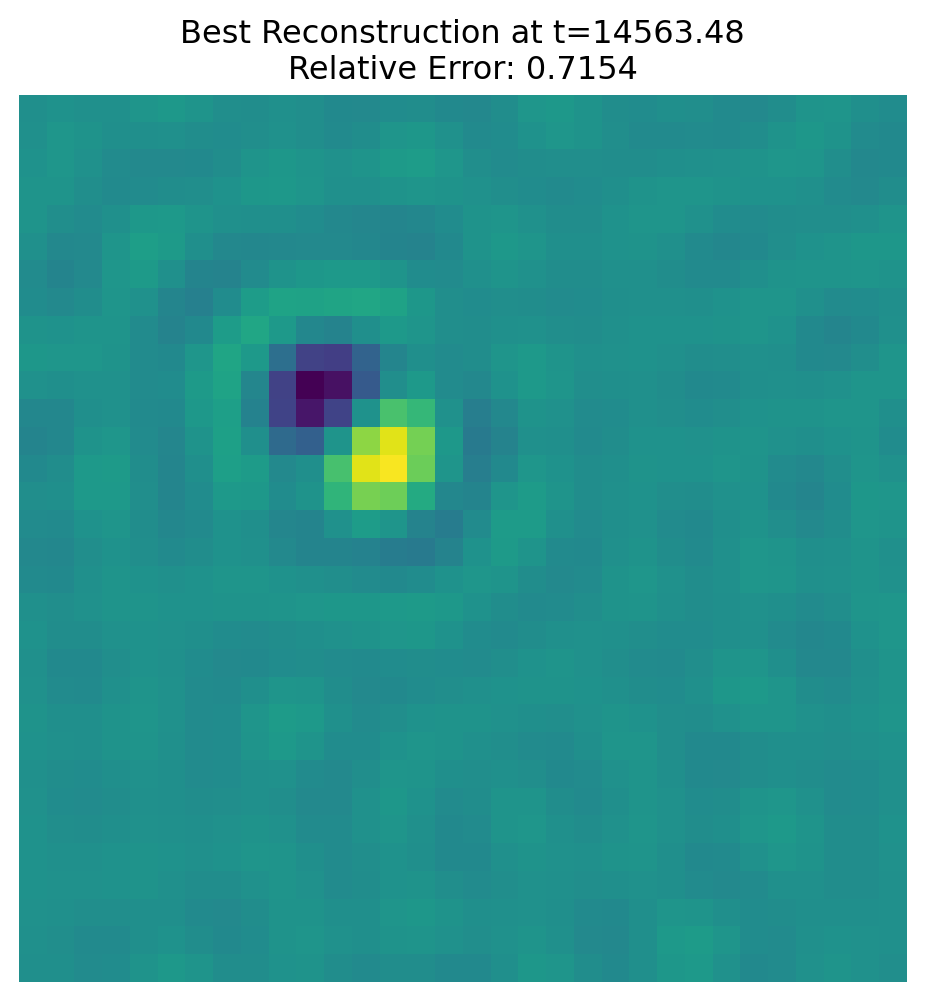
b = Amv(x)