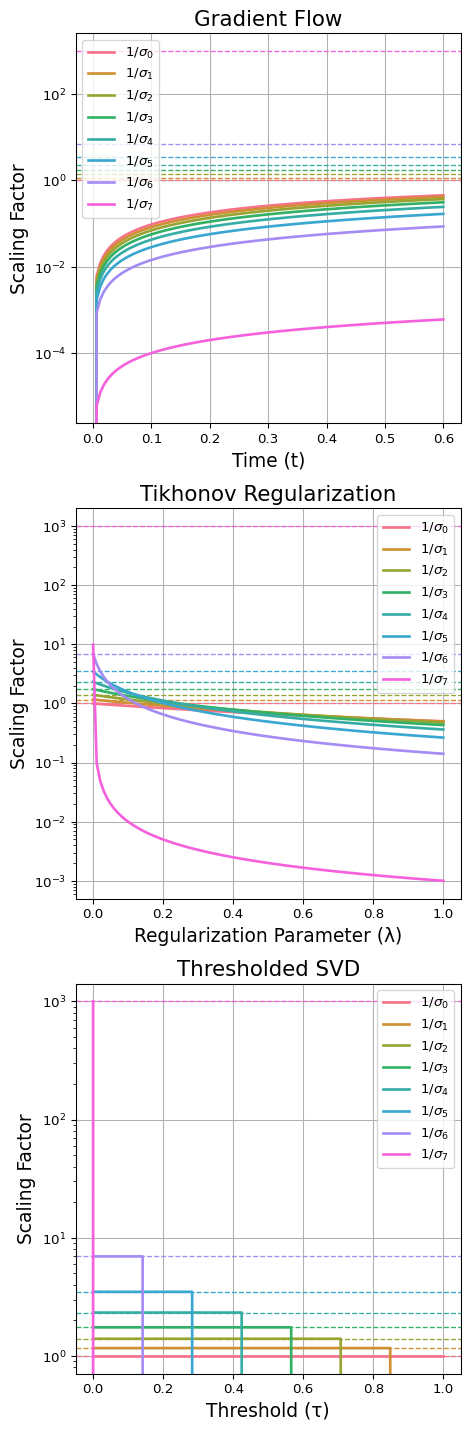
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
def generate_ill_conditioned_matrix(m, n, condition_number):
# Generate random orthogonal matrices U and V
U, _ = np.linalg.qr(np.random.randn(m, m))
V, _ = np.linalg.qr(np.random.randn(n, n))
sigma = np.linspace(1, 1/condition_number, min(m, n))
Sigma = np.diag(sigma)
A = U @ Sigma @ V[:min(m, n), :]
return A, sigma
# Seed for reproducibility
np.random.seed(4)
A, S = generate_ill_conditioned_matrix(8, 24, 1e3)
# Create a vector b of size 8 with random values
b = np.random.randn(8)
# Compute the SVD of A
U, S, Vt = np.linalg.svd(A, full_matrices=False)
V = Vt.T
U = U # Already in proper shape
# Number of singular values
n = len(S)
# Define parameters for each method
# Gradient Flow
t_values = np.linspace(0, 0.6, 100)
# Tikhonov Regularization
lambda_values = np.linspace(1e-4, 1, 100)
# Thresholded SVD
threshold_values = np.linspace(0, max(S), 100)
# Compute scaling factors for each method
# Gradient Flow Scaling
def gradient_flow_scaling(sigma, t):
return (1 - np.exp(-sigma**2 * t)) / sigma
gradient_scalings = np.array([gradient_flow_scaling(s, t_values) for s in S])
# Tikhonov Scaling
def tikhonov_scaling(sigma, lambd):
return sigma / (sigma**2 + lambd)
tikhonov_scalings = np.array([tikhonov_scaling(s, lambda_values) for s in S])
# Thresholded SVD Scaling
def tsvd_scaling(sigma, threshold):
return np.where(sigma >= threshold, 1/sigma, 0)
tsvd_scalings = np.array([tsvd_scaling(s, threshold_values) for s in S])
# Initialize the plot with 3 subplots
fig, axes = plt.subplots(3, 1, figsize=(5, 15))
# Define a color palette
palette = sns.color_palette("husl", n)
# Plot Gradient Flow
ax = axes[0]
for i in range(n):
ax.plot(t_values, gradient_scalings[i], color=palette[i], linewidth=2, label=f'$1/\sigma_{i}$' )
ax.axhline(y=1/S[i], color=palette[i], linestyle='--', linewidth=1)
ax.set_yscale('log')
ax.set_xlabel('Time (t)', fontsize=14)
ax.set_ylabel('Scaling Factor', fontsize=14)
ax.set_title('Gradient Flow', fontsize=16)
ax.legend()
ax.grid(True)
# Plot Tikhonov Regularization
ax = axes[1]
for i in range(n):
ax.plot(lambda_values, tikhonov_scalings[i], color=palette[i], linewidth=2, label=f'$1/\sigma_{i}$' )
ax.axhline(y=1/S[i], color=palette[i], linestyle='--', linewidth=1)
ax.set_yscale('log')
ax.set_xlabel('Regularization Parameter (λ)', fontsize=14)
ax.set_ylabel('Scaling Factor', fontsize=14)
ax.set_title('Tikhonov Regularization', fontsize=16)
ax.legend()
ax.grid(True)
# Plot Thresholded SVD
ax = axes[2]
for i in range(n):
ax.plot(threshold_values, tsvd_scalings[i], color=palette[i], linewidth=2, label=f'$1/\sigma_{i}$')
ax.axhline(y=1/S[i], color=palette[i], linestyle='--', linewidth=1)
ax.set_yscale('log')
ax.set_xlabel('Threshold (τ)', fontsize=14)
ax.set_ylabel('Scaling Factor', fontsize=14)
ax.set_title('Thresholded SVD', fontsize=16)
ax.legend()
ax.grid(True)
# Adjust layout and add a legend
plt.tight_layout()
plt.show()